Predictive maintenance as a project
.webp)


Solutions for predictive maintenance of machines
Manufacturing companies in Germany are investing loudly Federal Statistical Office over 50 billion euros per year in machines and systems. Efforts to prevent outages are correspondingly high. Predictive maintenance is therefore becoming a central component of Industry 4.0.
Production chains are becoming increasingly complex. As a result, they are significantly more frequently and more affected by deficiencies. An outdated maintenance strategy can reduce a site's production capacity by up to 20 percent. More and more companies are therefore using predictive maintenance. In contrast to preventive maintenance, “predictive maintenance” relies on predicting maintenance requirements for machines and systems in order to minimize downtime and reduce maintenance costs. Sensor data is used for this purpose, which many machines are already factory-equipped with.
Preventive maintenance means carrying out maintenance measures according to predefined criteria, for example changing a light source every 7,000 operating hours. Predictive maintenance, on the other hand, means that maintenance costs are automatically determined on the basis of key figures and the relationships between these indicators and optimized for low downtime and high machine efficiency. Compared to preventive maintenance, predictive maintenance can increase the availability of production plants by 10 to 20 percent, while maintenance costs fall by 5 to 10 percent.
How does predictive maintenance work?
In short, predictive maintenance, or predictive maintenance in Industry 4.0, means that the maintenance requirements of systems and machines are determined automatically and individually. In doing so, an algorithm is getting closer and closer to the optimal time for maintenance in order to minimize downtime and save costs. The optimal interval between maintenance can differ significantly between machines of the same model, as each machine is analyzed individually.
For predictive maintenance, an algorithm learns certain patterns from data that indicate a need for maintenance. Sensor data is used in almost every solution, but more and more systems are using additional image recognition or external information such as the type of material used. For example, fatigue in the material can be identified as a result of a change in sound. Sensors then record sound frequencies that are not audible to humans. This makes it possible to identify signs of an imminent defect up to two weeks earlier.
Collection of sensor data
Die data analysis is carried out using sensor data. A third of all machines used in Germany are already equipped with sensors. New models in particular are increasingly equipped with integrated sensors. Data such as temperature, operating time, speeds, pressure and vibration are used particularly frequently for predictive maintenance.
In principle, the following applies: With large amounts of data, the determination of maintenance costs is significantly more reliable. Many medium-sized companies that have so far had only a few points of contact with Big data and artificial intelligence , complain about obstacles to implementation, do not have the necessary competencies in the company and see high costs. But these challenges of Industry 4.0 can be met competently with the right long-term strategy.
Challenges and solutions for initial projects with predictive maintenance
Each company operates under individual circumstances, framework conditions, requirements and objectives. However, there are also some challenges that must be addressed regularly in predictive maintenance projects. These challenges can be categorized and then solved systematically.
data collection
Data is the basis for every learning algorithm. But first of all, these must be recorded. Data collection and data management work when data is collected, transferred, and stored. More and more systems have integrated sensors for this purpose, which automatically collect data.
Data collection solution
Data collection is a combination of several sub-processes. Each of these sub-processes should be subject to best practice standards. These standards offer two benefits: reusability and robustness. Functioning sub-steps can be used for other cases with slight adjustments. This reduces the effort required to set up and develop systems for data collection and yet they remain flexible. At the same time, a high quality standard is ensured. The individual components have been tried and tested in practice and optimized in such a way that the rapid construction of the system can be combined with high performance. The selection of specific tools is of paramount importance. experience with suitable technologies can immensely speed up the development of data collection and reduce long-term costs to a minimum.
data preparation
The entire data collection and all sub-steps are optimized to enable a smooth and fast process. For this purpose, data is packaged and compressed. As a result, data can be used very flexibly, while at the same time keeping storage and transfer costs low. However, in order for an algorithm to learn from data, it must be converted into a different format. In addition, data can always be incorrect or incomplete. High data quality is a prerequisite for reliable artificial intelligence. The so-called “Rule of Ten” is one of the most important rules when working with data. It states that work steps with high-quality data are 90% cheaper than with incorrect data because they are completed significantly faster and produce errors much less frequently.
Data preparation solution
Choosing the right tools is also crucial to ensuring high data quality. It is very important to develop effective processes to control data quality. An effective control process provides insights into which quality deficiencies exist and how they can be remedied.
The use of Engineering Best practices ensure that data quality can be kept at a high level. Tools such as dbt make it possible to implement best practices in data preparation even for young, small data teams. When properly configured, dbt ensures that deficiencies are identified before they actually occur.
data combination
Artificial intelligence is based on identifying rules and patterns in data. For this to happen, these patterns must be included in the data. One of the most important success factors for predictive maintenance projects is data enrichment. Certain regularities can only be revealed by adding further information.
Data combination solution
The combination of data from different source systems seems like an additional effort at first glance. In fact, this step can even reduce predictive maintenance costs and provide additional flexibility.
In order to identify useful options for data enrichment, professional experience in using the systems and machines is of paramount importance. Through the exchange of AI developers and production employees, possible connections are directly exchanged and can also be integrated into the predictive maintenance system in a very short time. All information used is judged according to its added value by comparing the improvements in performance and expenses. This comparison is automatic and is permanently available for further optimizations and for controlling.
Success factors for projects with predictive maintenance
The success of projects with predictive maintenance can certainly be predetermined if important basic requirements are met. In the area of classic data analysis Companies therefore urgently need to do their homework. Because there is one rule of thumb that must also be observed urgently in Industry 4.0: First data analytics, then data science.
Transparency of maintenance costs
Even if there is a sufficient database, this does not mean that it will also be seen. So that the data is not only collected on the server or in the cloud, but also visible, it must be visualized and made available to all responsible parties. Implementation can be carried out via dashboards, automated emails and integration with existing communication tools such as Slack or Trello. The work of a production manager or technical asset manager is reliably supplemented with this data, often delivered in real time. Professional data analysis Using a modern data stack is therefore considered a guarantee of success for predictive maintenance.
Prediction of maintenance costs
When and how much effort is required to maintain machines can be predicted using artificial intelligence and appropriate machine learning algorithms. Algorithms only make machines capable of learning. It is important that the measured data is smoothly monitored in order to make system diagnostics, automatically identify deviations and suspected problems, and make a forecast of the remaining useful life. Which AI algorithm is used depends on the monitored machine. A distinction is made between classification and anomaly detection. While classification is a useful way to monitor machines with a high failure rate, anomaly detection is used for devices that are barely susceptible to errors. Monitoring them is much more complex, as there are rarely any signs of failure here.
Raw data from sensors
Sensors that are already integrated into the system or can be installed with little effort are used for predictive maintenance. When it comes to the data to be collected, a distinction is made between necessary and additional data. Necessary data is a prerequisite for predictive maintenance. Additional data improves the quality of forecasts, but is not a must. The most important data to be collected is information about failures in the past, temperature, operating time, speeds, pressure, vibration and indirect parameters such as the material used or supplier. Which of these are necessary will be decided on a case-by-case basis.
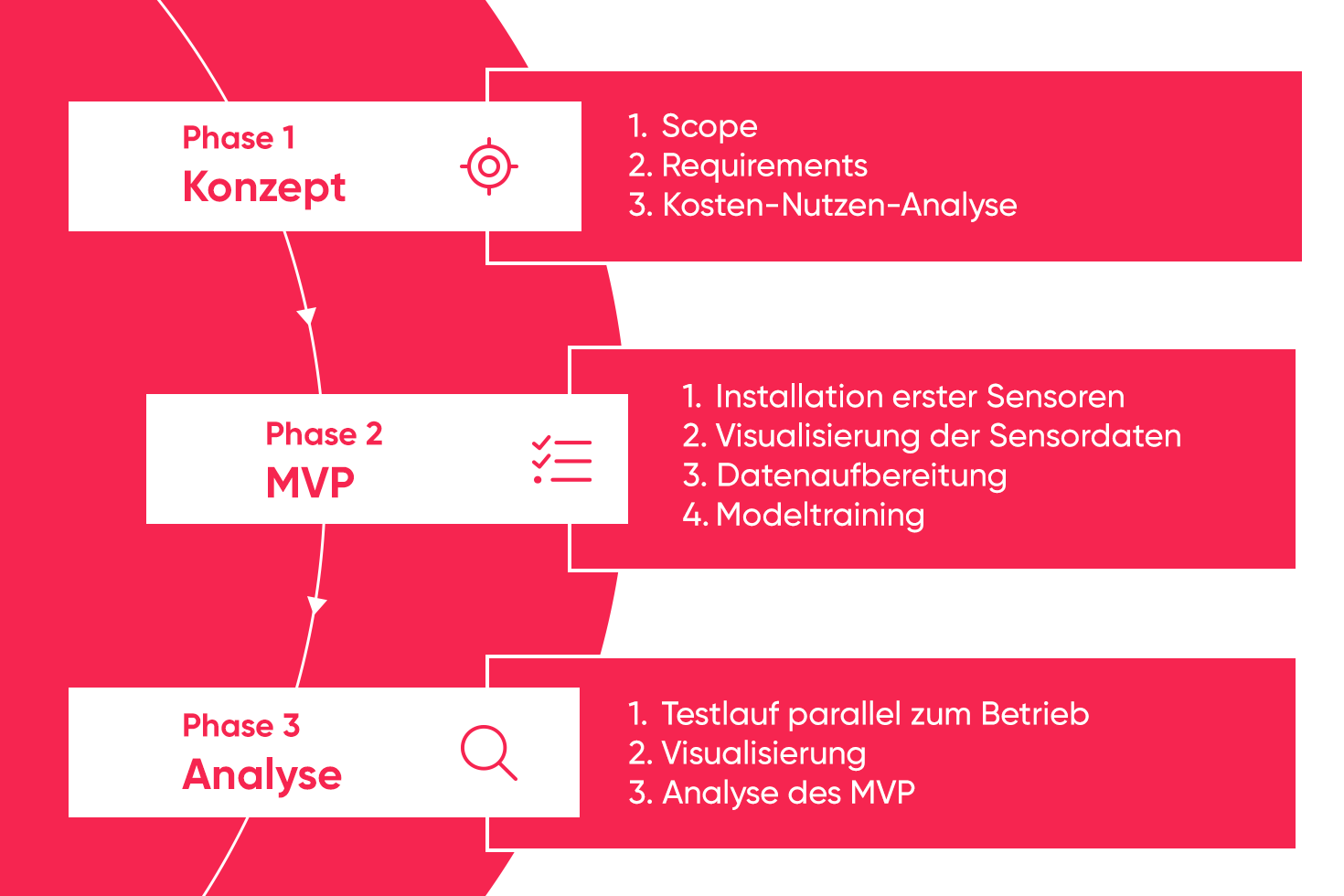
Process of a predictive maintenance project
A predictive maintenance project requires careful preparation, but can then be quickly put on track. Basically, it can be divided into three phases: concept, MVP and analysis: