Wie verläuft ein erfolgreiches Data-Science-Projekt?


Datenanalyse mit besonderen Herausforderungen
Um das volle Potenzial von Data Science im Unternehmen auszuspielen, spielen Projektsteuerung und Projektdurchführung eine besondere Rolle. Denn bei der Beantwortung von Fragen mittels Methoden aus dem Bereich Data Science beziehungsweise des Machine Learning ist es wichtig, sich über deren spezielle Anforderungen im Klaren zu sein. Nur so ergibt sich ein erfolgreiches Data-Science-Projekt.
Die Herausforderungen von Projekten im Bereich Data Science liegen zum einen in deren Komplexität, zum anderen auch in der prekären Vorhersagbarkeit von Zeit und Ressourcen zur Erreichung eines bestimmten Ziels.
Besonderheiten von Data-Science-Projekten
So kommt es bei der Umsetzung neben der Fragestellung essenziell auf die vorhandene Datengrundlage an. Nicht nur die Datenaufbereitung spielt hier eine Rolle, bei der meist vor der Anwendung der Algorithmen neue Merkmale modelliert werden müssen. Es ist auch durchaus möglich, dass ein Datensatz für Teilaspekte der Fragestellung noch keine ausreichenden Informationen enthält. Dann werden die Ansatzpunkte für das Projekt neu kalibriert. Diese Unschärfe sollte bei einem Data-Science-Projekt immer einkalkuliert werden.
Um erforderliche Fachkenntnisse der zu untersuchenden Fragestellung leisten zu können, ist ein stetiger Austausch mit Kunden und Kundinnen Grundvoraussetzung und für die Erstellung eines präzisen Modells empfehlenswert. Denn oftmals bilden Daten Prozesse ab, die Kenntnisse über deren Zusammenhänge verlangen, um sinnvolle Ableitungen zu erstellen.
Aus diesen Gründen bedarf es einer besonderen Vorgehensweise für ein Data-Science-Projekt, um den aufkommenden Herausforderungen flexibel zu begegnen.
Wie überall gilt auch bei Data Science: Fragen stellen!
Am Anfang von allem steht immer das Stellen von Fragen. Die können folgendermaßen lauten:
- Wie wird sich mein Geschäft in Zukunft entwickeln?
- Was führt dazu, dass Kunden meinen Service kündigen oder mein Produkt nicht mehr bestellen?
- Gibt es Kundengruppen, die ein ähnliches Verhalten aufweisen, sodass ich diese mittels personalisierter Werbung gezielter ansprechen könnte?
- Wie viele Produkte sollte ich im nächsten Monat auf Lager halten, um den Bedarf decken zu können?
- Wie kann ich meine Prozesse optimieren?
Je nach Unternehmen tauchen unterschiedlichste Fragestellungen auf und diese Liste von Fragen könnte endlos fortlaufend sein. Die wenigsten Unternehmen besitzen jedoch ausreichende Ressourcen im Bereich Data Science. Um ein erfolgreiches Projektvorgehen zu garantieren, empfiehlt sich daher die Zusammenarbeit mit externen Datenanalysten.
Use Cases identifizieren
Die Bewertung, ob die im Unternehmen aufgekommenen Fragen mittels geeigneter Machine Learning-Algorithmen grundsätzlich zu beantworten sind, ist der erste Schritt der gemeinsamen Zusammenarbeit. Vielleicht lassen sich Antworten auf Fragen auch bereits mit sehr geringem Aufwand aus den Daten ablesen. Aufwändige Analysen sind dann eventuell gar nicht notwendig. Dazu eignet sich ein persönliches Gespräch oder ein Workshop mit einem Data Scientist.
Der Data Scientist betrachtet die Fragestellungen hier aus einem methodenorientierten Blickwinkel. So kommen seine oder ihre Kenntnis der zur Verfügung stehenden Algorithmen beziehungsweise Verfahren und sein oder ihr statistisches Wissen zum Tragen. Zum anderen muss der Data Scientist gemeinsam mit dem Kunden oder der Kundin auch aus einer betriebswirtschaftlichen Perspektive für den zukünftigen Geschäftserfolg die Relevanz der Fragen und den Aufwand zur Umsetzbarkeit ihrer Beantwortung festlegen.
Aufwand-und-Nutzen-Kalkulation von Data-Science-Projekten
Natürlich stellt die Projektkalkulation einen wesentlichen Punkt dar: Wie aufwändig wird das Projekt? Und eignen sich meine Daten überhaupt zur Erstellung präziser Modelle?
Der zu erwartende Umfang eines Data-Science-Projektes hängt stark davon ab, welche Daten genutzt werden sollen. Und wie genau das Modell im Ergebnis sein soll sowie von vielen weiteren Faktoren, welche eine Umfangsschätzung nur bei Kenntnis der Projektparameter erlauben.
Haben sich eine oder mehrere relevante Fragestellungen herauskristallisiert, gilt es die Umsetzbarkeit mittels der durch das Unternehmen gesammelten Daten zu bewerten. Denn nicht jeder Datensatz eignet sich für die Anwendung der Verfahren und nicht jede Datengrundlage reicht für jede Fragestellung aus. Vielleicht sind die Daten auch grundsätzlich geeignet, aber es müssen noch relevante Schritte für die Datenverarbeitung gegangen werden. Optimal wäre hier eine Bewertung der gesamten Daten in Hinblick auf die Fragestellung.
Dieses Vorgehen erweist sich aber oftmals als schwierig, denn nicht jedes Unternehmen ist bereit, seine Daten an einen externen Dienstleister zur Verfügung zu stellen. Die gute Nachricht ist hier, dass oftmals schon repräsentative Beispieldaten ausreichen, um die Machbarkeit zu bewerten. So kann häufig mittels solcher Beispieldaten ein erstes Modell erstellt und der Aufwand der Projektdurchführung abgeschätzt werden. Dieses Vorgehen ermöglicht eine realistische Aufwands-, Zeit- und Ressourceneinschätzung und ist eine gute Basis für ein erfolgreiches Projekt.
Vorgehensweise bei Data-Science-Projekten
Die iterative Vorgehensweise bei Data-Science-Projekten hat sich als Standard etabliert. Liefert ein verwendetes Verfahren noch nicht die angestrebte Genauigkeit kann dies viele verschiedene Ursachen haben. Es ist zu Anfang eines solchen Projektes auch ganz normal. Möglicherweise ist der genutzte Algorithmus nicht für die Besonderheiten der vorliegenden Daten geeignet. Aus diesem Grund werden oftmals verschiedene Verfahren zur Modellerstellung verwendet und deren Genauigkeit verglichen. Zusätzlich können die verwendeten Parameter der Methoden optimiert werden.
Entscheidende Verbesserungen können oftmals allein durch eine enge Zusammenarbeit mit dem Kunden oder der Kundin erzielt werden, indem diese ihre Fachkenntnisse bezüglich des Problems an den Data Scientist weitergeben können. Die neu gewonnenen Informationen kann dieser dann bei der Modellerstellung nutzen, um bestimmte Merkmale zu verwenden oder neue zu generieren und diese dann in den Algorithmus einzuspeisen. Hier muss der Data Scientist Kreativität, Domänenwissen, ein Gefühl für Daten und Kenntnis der Algorithmen beweisen.
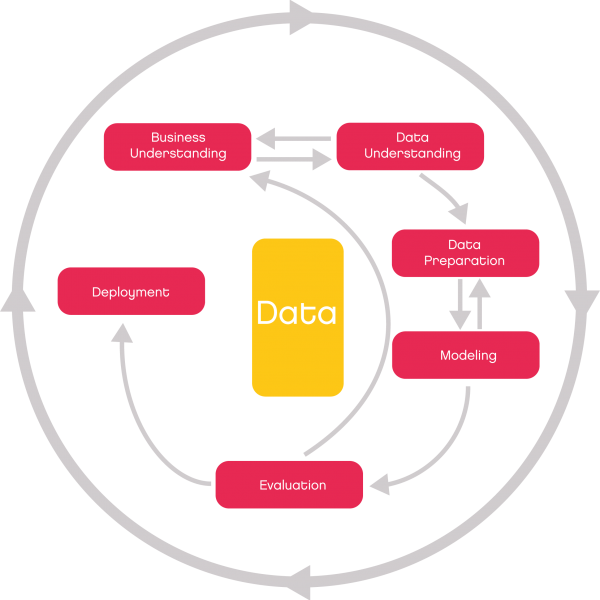
Vorteile des agilen Vorgehens bei Data Science
Aufgrund der speziellen Anforderungen eignet sich eine agile Vorgehensweise für Data-Science-Projekte besonders gut. Beim agilen Ansatz werden zu Beginn eines iterativen Zyklus Zwischenziele definiert. Die Ergebnisse aus diesen Zwischenzielen dienen als Basis für die nächste Zielsetzung im Projekt. So passen sich Kosten- und Ressourcenbudgets flexibel an den Projektverlauf an.
Das ist sinnvoll, da sich das Projekt sukzessive entwickelt. Anforderungen ändern sich, möglicherweise erschließen sich neue Datenquellen oder es ergeben sich aus den bereits gewonnenen Erkenntnissen neue Fragestellungen. Falls das Projektteam einen erheblichen Mehraufwand in einer frühen Projektphase feststellt, kann es flexibel darauf reagieren und den Projektverlauf abändern, ohne unnötige Kosten oder Ressourcenengpässe zu produzieren. Daher beginnt ein solches agiles Data-Science-Projekt mit einem ersten Basismodell, welches dann im weiteren Verlauf schrittweise optimiert wird und in die Hauptphase des Projekts übergeht, die durch das Erreichen von Meilensteinen gekennzeichnet ist.
Unsere Erfahrung zeigt, dass der agile Ansatz zu einer Steigerung der Effizienz, einer besseren Zusammenarbeit mit dem Kunden und einer höheren Kundenzufriedenheit beiträgt. In vielen wasserfallartigen Projekten führt die mangelnde Kommunikation zwischen den Beteiligten dazu, dass sich Erwartungen und Ergebnisse im Projektverlauf voneinander entfernen. Der agile Ansatz erlaubt es Unternehmen, in angemessener Zeit und Qualität sowohl auf vorhersehbare als auch auf unvorhersehbare Anforderungen zu reagieren und überzeugende Ergebnisse zu erzielen.
Die PPP-Regel: Planen, Probieren, Perfektionieren
Aufgrund der anfangs bestehenden planerischen Unschärfe erfordert jedes Data-Science-Projekt zu Beginn ein besonderes Gespür für die Projektparameter. Es kommt auf eine dezidierte Fragestellung und auf eine erste Bewertung an, ob die zur Verfügung stehende Datengrundlage eine solche Beantwortung zulässt.
Die Prüfung der Daten oder eines repräsentativen Teils muss definitiv zum Projektstart erfolgen. Da sie das Fundament für die darauf angewandten Algorithmen bildet, muss die Datenqualität als Grundvoraussetzung gegeben sein, um Aufwandsabschätzungen valide bestimmen zu können.
Gleichzeitig ist es im Projektverlauf unabdingbar, die Präzisierung der Parameter durch eine stetige Kommunikation mit dem Kunden oder der Kundin voranzutreiben. Nur so kann letztlich auch ein präzises Modell erstellt werden. Das geht nur über einen iterativen und gleichzeitigen agilen Ansatz. Denn Erkenntnisse in der Datenanalyse sind nicht nur das Endprodukt, sondern fallen im Prozess kontinuierlich an.



