How does a successful data science project work?


Data analysis with particular challenges
In order to exploit the full potential of data science in companies, project management and project implementation play a special role. Because when answering questions using methods from the fields of data science or machine learning, it is important to be aware of their specific requirements. This is the only way to create a successful data science project.
The challenges of data science projects lie on the one hand in their complexity and on the other hand in the precarious predictability of time and resources to achieve a specific goal.
Special features of data science projects
In addition to the question, implementation also depends on the existing data basis. It is not only data preparation that plays a role here, in which new features usually have to be modelled before the algorithms are applied. It is also entirely possible that a data set does not yet contain sufficient information for partial aspects of the question. The starting points for the project are then recalibrated. This uncertainty should always be taken into account in a data science project.
In order to be able to provide the necessary expertise in the question to be investigated, continuous exchange with customers is a basic requirement and recommended for the creation of a precise model. Because data often depicts processes that require knowledge of their interrelationships in order to create meaningful derivations.
For these reasons, a data science project requires a special approach in order to flexibly meet emerging challenges.
As everywhere else, the same applies to data science: ask questions!
Everything always starts with asking questions. They can read as follows:
- How will my business develop in the future?
- What causes customers to cancel my service or stop ordering my product?
- Are there customer groups that have similar behavior so that I could target them more specifically through personalized advertising?
- How many products should I keep in stock over the next month to meet demand?
- How can I optimize my processes?
Depending on the company, a wide variety of questions arise and this list of questions could be endless. However, very few companies have sufficient resources in the area of data science. Cooperation with external data analysts is therefore recommended in order to guarantee a successful project approach.
Identify use cases
Evaluating whether the questions that have arisen in the company can be answered in principle using suitable machine learning algorithms is the first step of joint cooperation. Perhaps answers to questions can be derived from the data with very little effort. Complex analyses may then be unnecessary at all. A personal conversation or a workshop with a data scientist is suitable for this purpose.
The data scientist looks at the issues here from a methodological perspective. In this way, his or her knowledge of the available algorithms or methods and his or her statistical knowledge come into play. On the other hand, the data scientist, together with the customer, must also determine the relevance of the questions and the effort required to implement their answers from a business perspective for future business success.
Cost and benefit calculation of data science projects
Of course, the project calculation is an important point: How complex will the project be? And is my data even suitable for creating precise models?
The expected scope of a data science project depends heavily on which data is to be used. And how exactly the model should be as a result, as well as of many other factors that only allow a scope estimate if the project parameters are known.
Once one or more relevant issues have emerged, the feasibility must be assessed using the data collected by the company. This is because not every data set is suitable for applying the methods and not every data basis is sufficient for every question. Perhaps the data is also suitable in principle, but relevant steps still need to be taken for data processing. An evaluation of the entire data with regard to the question would be ideal here.
However, this procedure often proves difficult, as not every company is prepared to make its data available to an external service provider. The good news here is that representative sample data is often sufficient to assess feasibility. In this way, a first model can often be created using such sample data and the cost of project implementation can be estimated. This approach enables a realistic estimate of costs, time and resources and is a good basis for a successful project.
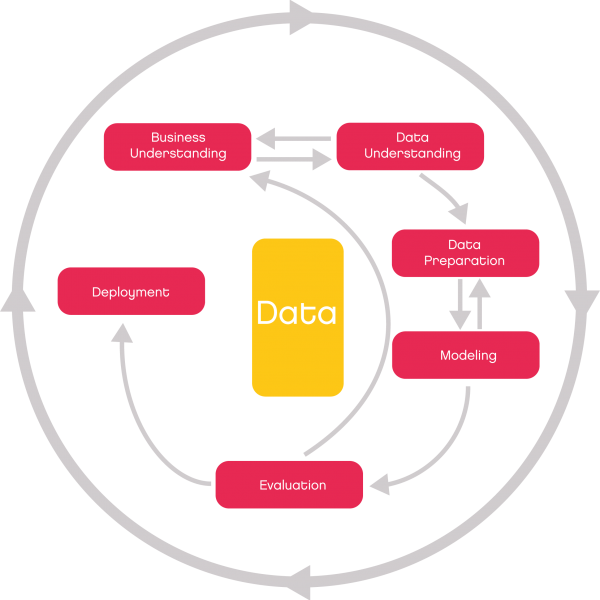
Approach to data science projects
The iterative approach to data science projects has established itself as the standard. If a method used does not yet deliver the desired accuracy, this can have many different reasons. It is also quite normal at the start of such a project. The algorithm used may not be suitable for the specific features of the available data. For this reason, different methods are often used to create models and compare their accuracy. In addition, the parameters used for the methods can be optimized.
Decisive improvements can often be achieved through close cooperation with the customer alone, by allowing them to pass on their expertise regarding the problem to the data scientist. The user can then use the newly acquired information when creating the model to use certain features or generate new ones and then feed them into the algorithm. Here, the data scientist must demonstrate creativity, domain knowledge, a feeling for data and knowledge of algorithms.
Benefits of an agile approach to data science
Due to the special requirements, an agile approach is particularly suitable for data science projects. In the agile approach, interim goals are defined at the start of an iterative cycle. The results from these interim goals serve as the basis for the next goal in the project. In this way, cost and resource budgets can be flexibly adapted to the course of the project.
This makes sense, as the project is gradually developing. Requirements are changing, new data sources may be opened up or new questions may arise from the knowledge already gained. If the project team finds significant additional work in an early project phase, they can react flexibly and change the course of the project without producing unnecessary costs or resource bottlenecks. Therefore, such an agile data science project starts with a first basic model, which is then gradually optimized as it progresses and moves on to the main phase of the project, which is characterized by the achievement of milestones.
Our experience shows that the agile approach increases efficiency, contributes to better cooperation with customers and higher customer satisfaction. In many waterfall-like projects, the lack of communication between those involved means that expectations and results diverge from each other over the course of the project. The agile approach allows companies, within a reasonable amount of time and quality, to both predictable and to react even to unforeseeable requirements and achieve convincing results.
The PPP rule: Plan, try, perfect
Due to the initial planning uncertainty, every data science project requires a special sense of the project parameters at the beginning. It depends on a specific question and an initial assessment as to whether the available data basis allows such an answer.
The data or a representative part of it must definitely be checked at the start of the project. Since it forms the basis for the algorithms applied to it, data quality must be met as a basic requirement in order to be able to validly determine cost estimates.
At the same time, it is essential to press ahead with the clarification of the parameters through continuous communication with the customer during the course of the project. This is the only way to ultimately create a precise model. This is only possible with an iterative and simultaneous agile approach. This is because findings in data analysis are not only the end product, but are also continuously generated during the process.

.webp)

